

生成AIは今やビジネスの現場では欠かせない存在となり、日常業務の効率化から新しい価値の創出まで、日々さまざまなシーンでその広がりを見せています。
なかでも、いま最も注目を集めているAIチャットボットが「ChatGPT」と「Grok」です。両者は同じ対話型AIという特徴を持ちながら、使える機能や得意な領域については若干の違いがあります。
本記事では、そんなChatGPTとGrokについて、文章生成やコーディングから、画像解析やデータ分析まで、合わせて10個のテスト項目を用意して徹底比較*していきます。
AIチャットボットとして世界的な知名度を誇る両者ですが、果たしてどちらのAIがより優れているのでしょうか?AI同士のプライドを賭けた十番勝負がいま幕を開けます。
※ 本記事は米国の『G2.com』からコンテンツ提供を受けて掲載しています。
参照:G2 Learn – I Put Grok vs ChatGPT Head to Head and One Stood Out
* 2025年6月時点における、あくまで「個人的な感想」にもとづいた調査レポートです。実際のAI性能や生成結果を保証するものではありません。
ChatGPTとGrokの概要整理
まずは実際の勝負を始める前に、ChatGPTとGrokそれぞれの違いや共通点を整理しておきましょう。
| 項目 | ChatGPT | Grok |
|---|---|---|
| G2評価 | 4.7 / 5 | 4.4 / 5 |
| AIモデル | 無料版:GPT-4o Mini 他有料版:GPT-4.5, o1, o3-mini-highなど | 無料版:Grok 3 他有料版:SuperGrok (拡張アクセス) |
| 得意分野 | 汎用利用 (執筆・コーディング・画像生成) | 簡潔な要約、リアルタイム情報、カジュアルコンテンツ |
| 強み | 構造化・正確性・幅広い統合機能 | ユーモア・スピード・リアルタイム性 |
| 料金 | Plus:$20/月 Pro:$200/月 | SuperGrok:$30/月 または $300/年 |
ChatGPTとGrokは名前こそ異なるものの、その中身は想像以上に似ています。トーンやブランディングの違いはさておき、どちらもあらゆるデジタルタスクに対応できる優れたマルチモーダルAIツールとして設計されています。
ChatGPTとGrokの違い
| 項目 | ChatGPT | Grok |
|---|---|---|
| 哲学と個性 | 頼れる勉強仲間のように礼儀正しく明快。やや堅めで、真剣なタスクに最適。 | 皮肉っぽくユーモラス。人間味があり楽しいが、繊細なタスクには不向きな場合もある。 |
| AIモデル | OpenAIのGPTファミリー。無料: GPT-4o mini有料: GPT-4o, GPT-4.5, o1, o3-mini, o3-mini-high | xAI開発のGrok-3を採用。長文推論とリアルタイム更新を重視。 |
| コンテキストウィンドウ | GPT-4oで128Kトークン処理可能。大半の業務で十分。 | 最大100万トークン対応。非常に長い会話や複雑プロンプトに最適。 |
| 知識のカットオフ | 2023年10月まで更新済み。ブラウジングで最新情報追加可能。構造化調査に強み。 | 厳格なカットオフなし。XとWebからリアルタイム取得。ただし文脈や信頼性が課題になる場合あり。 |
| プラットフォームエコシステム | AI生産性ハブとして進化。カスタムGPT、チームワークスペース、ファイル分析、プロジェクト作成などが可能。 | シンプルなアシスタント型。カスタムボットや統合機能は未提供。自己完結的。 |
| アクセシビリティ | chat.openai.com、iOS/Androidアプリで利用可能。プラットフォーム非依存。 | X.com、iOS/Androidアプリ、grok.comで利用可能。特にトレンド情報はXに強く依存。 |
| ファイル処理 | PDF、DOCX、TXT、PPTXなどに対応。最大512MB/ファイル。無料ユーザーは1日3ファイルまで。GPT-4oで高精度解析・要約が可能。 | DOCX、XLSX、CSVなどをサポート。OneDrive・Google Workspaceと連携。ただしサイズ上限や利用制限は非公開。 |
ChatGPTとGrokの共通点
| 項目 | ChatGPT | Grok |
|---|---|---|
| ライティング支援 | レポート要約、記事下書き、アイデア出しなどに優れ、幅広い用途に対応。構造的で精度の高い文体。 | 同様に幅広いコンテンツ生成が可能。ユーモラスでカジュアルな文体に強み。 |
| コーディング支援 | Python、SQL、JavaScriptなどを高精度で対応。コード生成・デバッグ・最適化の完成度が高い。 | 幅広い言語をサポート。精度はやや劣るが、一般的なタスクは十分に処理可能。 |
| ボイスチャット | 音声入力・音声出力の両方に対応。直感的で自然な会話体験を提供。 | 同様に音声対応。ハンズフリー操作でのインタラクションに有効。 |
| マルチモーダル | テキスト・画像・音声を統合。特にGPT-4oで高度な画像解釈とスムーズな音声対話を実現。 | テキスト・画像・音声に対応。ただし視覚推論の深さは限定的。動画入力は未対応。 |
| ウェブリサーチ | SearchGPTでWebにアクセスし、引用付きの構造化調査結果を提供。複雑テーマの掘り下げに適する。 | DeepSearch/DeeperSearchでWeb全体を探索。文脈豊富な情報収集と探索的リサーチに特化。 |
対戦ルール
今回の対決のルールについても、あらかじめ整理しておきましょう。特に「評価領域」と「評価基準」については、どちらか一方が有利になってしまわないよう、なるべく公平性と客観性をもったルールの設計が重要です。
評価領域
評価領域については、以下の10個の課題でテストするものとします。
| 評価領域 | 内容 |
|---|---|
| ①:要約文作成テスト | 対象の記事を3つの箇条書き(1つ50語未満)で要約する |
| ②:創作文作成テスト | 指定した条件で300語のSFシーンを物語調で作成する |
| ③:コンテンツ作成テスト | 指定した条件で架空製品のブランドキットを作成する |
| ④:アプリ開発テスト | パスワードジェネレーターを即時実装レベルで作成する |
| ⑤:画像生成テスト | ブティック店のオーナーをストックフォト調で生成する |
| ⑥:画像解析テスト | インフォグラフィック図解と手書きメモ画像を読み取る |
| ⑦:ファイル分析テスト | 論文のPDFファイルを100語未満の5つの箇条書きで要約する |
| ⑧:データ分析テスト | GoogleトレンドのCSVからデータの可視化と傾向を分析する |
| ⑨:リアルタイム検索テスト | 直近で重要なAIに関連するニュース記事を3つ取得する |
| ⑩:ディープリサーチテスト | AIチャットボットの現状に関するレポートを作成する |
テストの実施にあたっては、それぞれのAIに全く同じプロンプトを正確に送信しました。カスタム指示や書き換え、モデル固有の調整は一切行っていません。
また、このプロンプトは、比較的妥当なベンチマークデータとなるよう、Gemini、Perplexity、DeepSeekといった他のチャットボットの検証でも使用しています。
評価基準
評価基準については、以下の4つの観点から評価するものとします。
| 評価基準 | 内容 |
|---|---|
| ①:正確性 | 事実に基づいた信頼できる情報であるか? |
| ②:創造性 | ユニークで思慮深く、適切に構成されているか? |
| ③:明瞭性 | 読みやすく論理的で、そのままの利用が可能か? |
| ④:実用性 | 大幅な編集をせずにワークフローへ組み込めるか? |
テスト実施者だけの評価では、どうしても主観的な評価に偏ってしまうため、上記の評価基準に加えて、G2のユーザーレビューと検証結果を照らし合わせて、評価の妥当性を検証しました。
現時点では、まだGrokのレビューは十分に蓄積されていない一方で、ChatGPTは多数のユーザー評価が存在します。こうしたポイントも加味したうえで、なるべく公平な評価になるよう心がけました。
免責事項: AIの応答は、同じプロンプトであっても、フレーズやセッション履歴、システムアップデートなどによって異なる場合があります。今回のテスト結果は、あくまでもテスト実施時点でのモデルの能力を反映しています。
対戦開始
ではいよいよ、ここからはChatGPTとGrokの実際のパフォーマンスを見ていきます。まずは要約テストからです。
①:要約文作成テスト
課題:対象の記事を3つの箇条書き(1つ50語未満)で要約する
このテストではChatGPTとGrokの両方に、対象の記事を3つの箇条書きで要約するよう依頼しました。比較的単純なテストですが、与えられた指示をどれだけ忠実かつ正確に遵守できるのでしょうか?
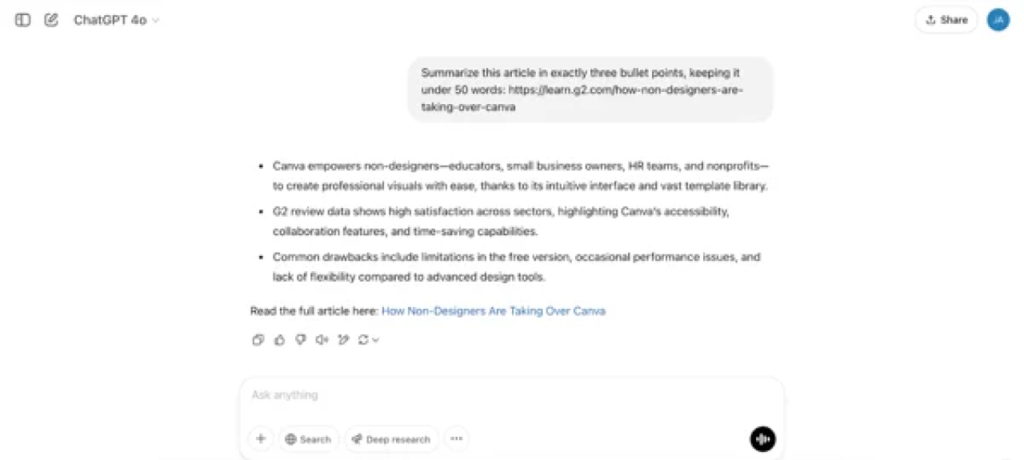
ChatGPTは要点の深堀りが上手な一方で、文字数制限は超過しがちな印象でした。コンパクトな要約というよりは、記事全文の抜粋のような内容で、簡潔さと正確さを追求する今回の趣旨としては、その目的を果たせませんでした。
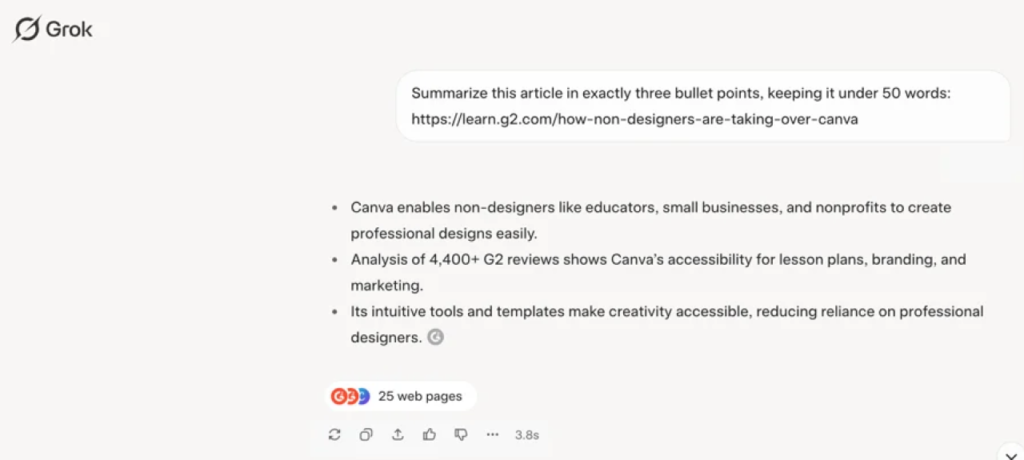
一方のGrokは制限を厳守したうえで、記事内のレビュー数などの実数値を正確に抽出して、短く要点を提示してくれました。ソースタブが複数表示されるUIは、最初はやや戸惑いがあるものの、出力はノイズが少なく実務に投入しやすい印象です。
勝者:Grok 👑
ChatGPTの回答は思慮深くはあるものの、指示の遵守と情報の正確性では一歩及びませんでした。一方のGrokは指示を完璧に理解し、タスクへの遵守がより明確な印象です。このラウンドはGrokの勝利としておきましょう。
②:創作文作成テスト
課題:指定した条件で300語のSFシーンを物語調で作成する
このテストではChatGPTとGrokの両方に、300語のSFシーンを物語調で作成するよう依頼しました。情緒的な創作文は一見するとAIの苦手分野のようにも思えますが、創造性に期待したいところです。

ChatGPTはタイトル付与「放浪者のささやき」などの編集的所作が秀逸(指示されずにタイトルをつけたのでボーナスポイント)で、よりシャープで会話重視の文章です。特に終盤のどんでん返しは心理的なパンチが効いていて印象的でした。

一方のGrokは映画的な雰囲気を漂わせ、雰囲気のある描写と徐々に盛り上がっていく展開が、真の孤独感と緊張感を生み出していました。また、生成した文章には明確な起承転結があり、感情的な結末もうまく描かれていたのが印象的です。
勝者:ChatGPT 👑
ChatGPTは構成と映画的なインパクトで勝っており、より力強いクライマックスと緻密な散文が特徴です。一方のGrokは雰囲気とテンポの良さで勝っています。僅差ではありますが、この勝負はChatGPTの勝利としておきましょう。
③:コンテンツ作成テスト
課題:指定した条件で架空の製品のブランドキットを作成する
このテストではChatGPTとGrokの両方に、製品のブランドキットを作成するよう依頼しました。1つのプロンプトには複数のアセット(メール本文、製品説明、タグラインなど)を提示しています。

ChatGPTの出力結果で特に印象的だったのは「あなたのスマートフォンに電力を供給すれば、地球に電力を供給できる」というキャッチフレーズです。パンチが効いていて、おそらくどちらのボットも思いついた中では最も力強いフレーズでした。
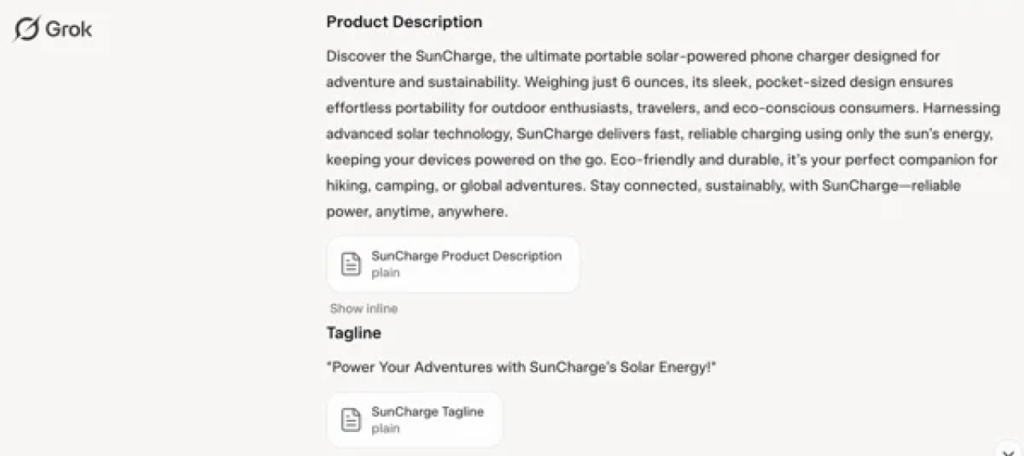
一方のGrokも負けていません。簡潔で一貫性があり、驚くほどブランド志向な印象でした。力強いキャッチフレーズから、InstagramやXにおけるプラットフォーム特有の言葉遣いまで、あらゆる観点で製品のペルソナを理解しているかのように書かれていました。
勝者:引き分け
ChatGPTは構造、明瞭性、そして見出しにふさわしいキャッチコピーを考えてくれました。一方のGrokは個性と視覚的なストーリーテリングをもたらしています。どちらも実務レベルであるため、この勝負は引き分けにしておきましょう。
④:アプリ開発テスト
課題:パスワードジェネレーターを即時実装レベルで作成する
このテストではChatGPTとGrokの両方に、簡易なパスワードジェネレーターを作成するよう依頼しました。コーディングスキルのない非エンジニアにとってAIがどれだけ役に立つのか検証していきます。
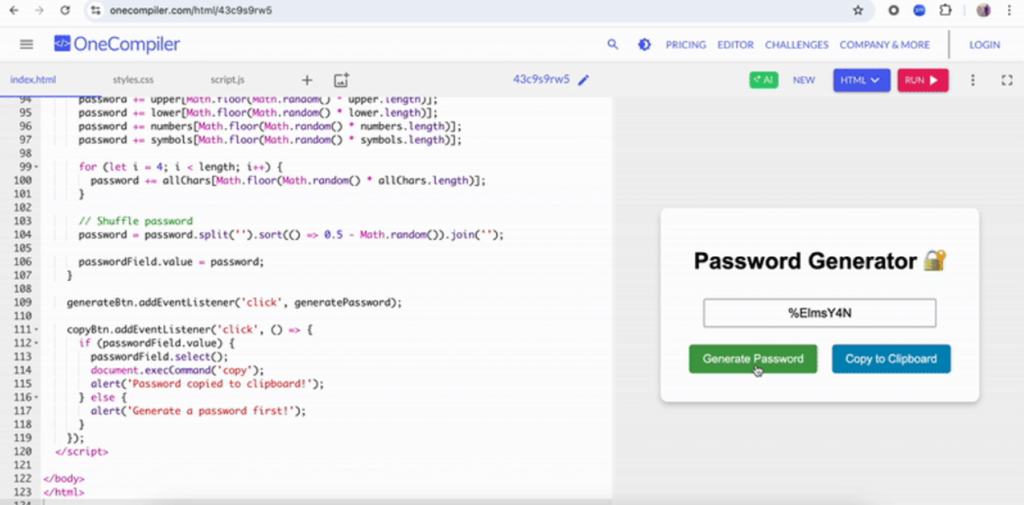
ChatGPTは完璧なコードを提供してくれました。編集も調整も一切不要で、そのままコンパイラで実行することができます。インターフェースもすっきりしていて、クリップボードへのコピーボタンも期待通りの動作をしました。
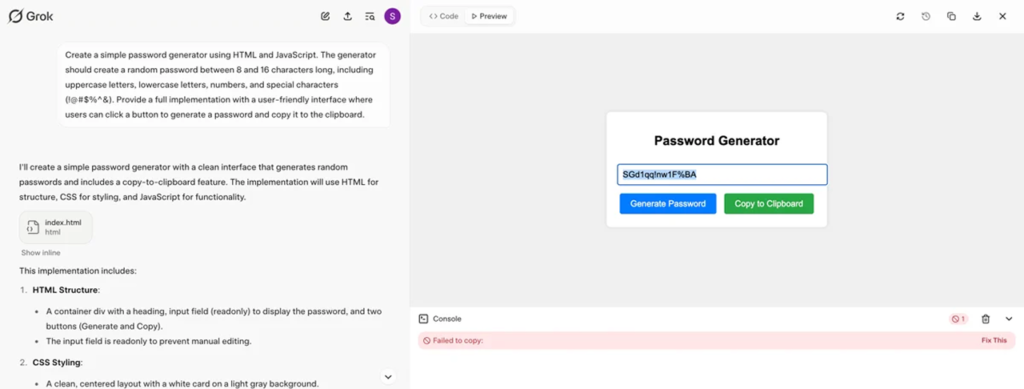
一方のGrokは分かりやすいコードとプレビューインターフェースを備えたスタイルのジェネレーターを作成してくれましたが、クリップボードへのコピー機能は動作しませんでした。これは私のような非エンジニアにとっては致命的な問題です。
勝者:ChatGPT 👑
Grokは私のような技術に詳しくない人間にとっても使いやすいという点で大きなアドバンテージを獲得しましたが、やはり提供されたコピー機能のエラーが致命的です。この勝負はChatGPTの完勝ということで良いでしょう。
⑤:画像生成テスト
課題:ブティック店のオーナーをストックフォト調で生成する
このテストではChatGPTとGrokの両方に、ストックフォト調の画像を生成するよう依頼しました。ロボットのような印象を消しつつ、自然で信憑性のある画像の生成に期待したいところです。

ChatGPTが生成した画像は構図・被写体のポーズ・雰囲気・ライティングが自然で、まるでプレミアムストックサイトからそのまま切り取ったような写真でした。販促バナーやLPなどにもそのまま使えるレベルといえます。

一方のGrokが生成した画像は少し物足りない印象を受けました。全体的なテーマは捉えているものの、照明は温かみや没入感に欠け、完成度が低い印象です。極めつけは手がぎこちなく、少し崩れているように見えることでした。
勝者:ChatGPT 👑
Grokはテーマへの理解は正しいものの、手指の違和感や背景の簡素さが目立った一方、ChatGPTは雰囲気や細かなディテール、そして最終的な出力まで完璧に再現していました。この勝負もChatGPTの勝利として良いでしょう。
⑥:画像解析テスト
課題:インフォグラフィックと手書きのメモを読み取る
このテストではChatGPTとGrokの両方に、データの図解と手書きのメモの解析を依頼しました。1 つはデータが詰まったインフォグラフィック、もう 1 つはエミリー ディキンソンの詩「希望とは羽のあるもの」全文を引用した手書きのメモです。

インフォグラフィックでは、両ツールとも6つの主要なデータポイントを抽出し、明確な要約を示してくれました。Grokは部門間の差異などトレンド示唆を付記したのに対して、ChatGPTは短く的を射た要約で読みやすさを優先するといった特徴が伺えます。

また、手書きの詩についても、両モデルとも正確に転記してくれました。Grokは私が尋ねた通り、焦点を絞って事実にもとづいた表現をしてくれました。ChatGPTは紙質や筆跡の特徴に言及するなど、少し個性を加えた出力結果が印象的でした。
勝者:引き分け
どちらも十分実用的なレベルであったため、この勝負は引き分けです。簡潔で要点を押さえた分析が欲しいならGrokを、もう少し解釈や洞察を加えて欲しいならChatGPTの利用が役に立つでしょう。
⑦:ファイル分析テスト
課題:論文のPDFファイルを100語未満の5つの箇条書きで要約する
このテストではChatGPTとGrokの両方に、アインシュタインのPDF論文の要約を依頼しました。果たして、密度の高い学術的なコンテンツをAIはどれだけ正しく処理できるのでしょうか?

ChatGPTは文字数をわずかに超過しましたが、これはちょっとしたパターンとして気付き始めています。とはいえ肝心な要約は正確で、アインシュタインが果たした現代物理学への貢献について、より解釈的な文脈があったのが印象的でした。

一方のGrokはこれまで通り要点を忠実に守り、簡潔で的確な要約をすっきりとしたフォーマットで提示してくれました。文字数制限内に収めているところも流石です。論点も正確で、特殊相対性理論の中核原理と見事に整合していたのが印象的でした。
勝者:Grok 👑
ChatGPTも素晴らしい要約を提供してくれましたが、精度と指示への追従性を重視するなら、今回はGrokの勝利として良いでしょう。Grokは文字数制限と構造を厳格に順守し、ChatGPTは制約をわずかに超過しつつも、解釈や補足といった部分が充実していました。
⑧:データ分析テスト
課題:GoogleトレンドのCSVからデータの可視化と傾向を分析する
このテストではChatGPTとGrokの両方に、指定したCSVファイルの分析を依頼しました。CSVファイルの内容は「米国におけるChatGPTの検索インタレスト(3ヶ月分)」を与えています。
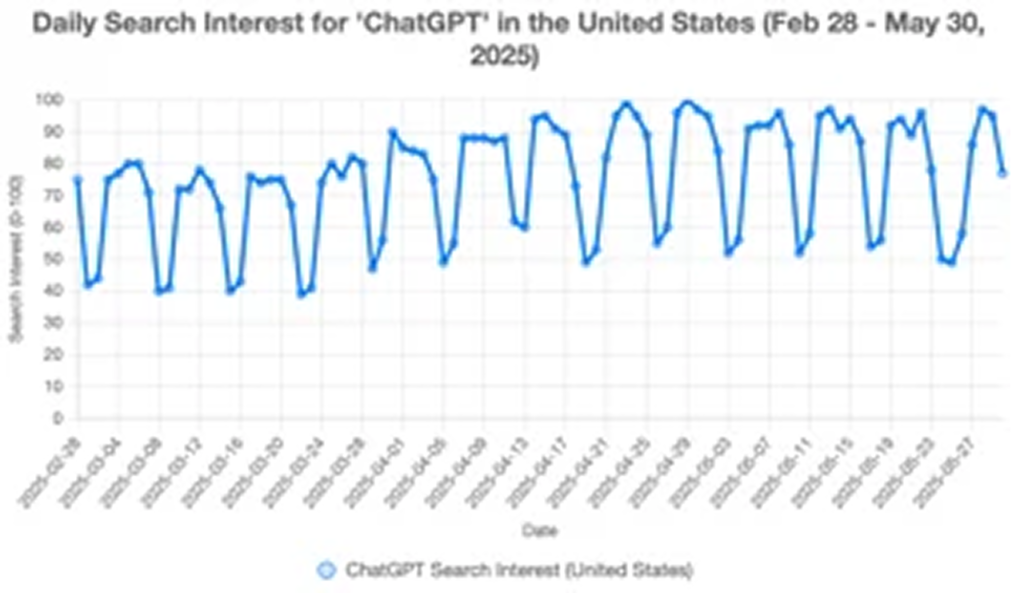
ChatGPTはパターンを強調するだけでなく、統計的な深みも備えていました。平均値や中央値、標準偏差やパーセンテージといった各指標を含む概要表も表示してくれました。また、グラフ上に7日間の移動平均線を描画したことは特筆すべきポイントといえるでしょう。

一方のGrokは平日と週末の行動の違いや具体的なピーク日といったトレンドを自然な言葉で示してくれました。深く掘り下げるための提案を行ってくれたのも高評価です。ただし、ストーリーテリングという観点では評価できるものの、数学的な分析までは一歩及ばない印象です。
勝者:ChatGPT 👑
どちらのツールもトレンドを明確に分類し、折れ線グラフで推移を可視化することができました。両者ともに素晴らしい結果でしたが、ChatGPTの方がより厳密で詳細な分析を提示してくれたため、この勝負はChatGPTの勝利です。
⑨:リアルタイム検索テスト
課題:直近で重要なAI関連のニュース記事を3つ取得する
このテストではChatGPTとGrokの両方に、AI関連の最新ニュースを取得するよう依頼しました。特に、X(旧Twitter)へのアクセスが直接できるGrokの提案結果には注目したいところです。

ChatGPTが取得した記事は、Grammarlyの10億ドルの資金調達、がん治療薬予測におけるAIの画期的な進歩、Amazonとニューヨーク・タイムズの新たなライセンス契約など、最新のニュースを抽出してくれました。複数の信頼できるソースから裏取りしており、鮮度と信頼性を両立しています。
一方のGrokが取得したニュース記事は、1週間以上前のものが混在しており、AIとの関連性は認められるものの、最新のニュースという感じではなかったことが少し残念でした。とりわけBBCの記事には大きく依存しており、メディアを横断したリアルタイム検索は課題が残る結果となりました。
勝者:ChatGPT 👑
なんとも意外な結果になりました。このテストでは当初、Grokが優勢だろうと予想していたのですが、驚いたことに、ChatGPTの提示した記事の方が明らかに鮮度が高く、信頼性の高いものでした。この勝負はChatGPTの圧勝です。
⑩:ディープリサーチテスト
課題:AIチャットボットの現状に関するレポートを作成する
このテストではChatGPTとGrokの両方に、エグゼクティブレベルのレポート作成を依頼しました。ChatGPTのDeep ResearchとGrokのDeepSearch、どちらがより複雑な情報を調査できるのでしょうか?

ChatGPTは生成目標を明確にするため、追加の質問をしてくれました。この時点で高評価です。最終レポートは明快で整理されており、役員会議にふさわしいトーンが備わっていました。奥深さと読みやすさのバランスが非常に優れている印象です。
GrokはDeepSearchとDeeperSearchの両方を活用し、視覚的にわかりやすい内容のレポートを2つ作成してくれました。チャットボットの進化から市場動向、プラットフォームの比較まで、幅広い情報を網羅しています。ただし、文章のトーンや流れには揺らぎが見えたため、その点はマイナスです。
勝者:ChatGPT 👑
この勝負はChatGPTの勝利です。目標の明確化のために適切な追加質問をしてきたことが決め手になりました。Grokは文章のトーンや流れの揺らぎに懸念が残ります。
対戦結果
これまでのテスト結果を表形式で振り返ってみましょう。勝負の結果は以下のようになりました。
| テスト内容 | ChatGPT:6勝2分2敗 | Grok:2勝2分6敗 |
|---|---|---|
| ①:要約文作成テスト | – | 👑 |
| ②:創作文作成テスト | 👑 | – |
| ③:コンテンツ作成テスト | – | – |
| ④:アプリ開発テスト | 👑 | – |
| ⑤:画像生成テスト | 👑 | – |
| ⑥:画像解析テスト | – | – |
| ⑦:ファイル分析テスト | – | 👑 |
| ⑧:データ分析テスト | 👑 | – |
| ⑨:リアルタイム検索テスト | 👑 | – |
| ⑩:ディープリサーチテスト | 👑 | – |
勝負の結果、6勝2分2敗で見事ChatGPTが勝利を収めました。GPT-4oとDeep Researchを組み合わせることで、クリエイティブワークフローと分析ワークフローの両方において、構造化された出力を一貫したクオリティで提供してくれました。
惜しくも敗れてしまったGrokも、本当に私を驚かせてくれました。的確な要約機能や強力なファイル処理能力、そしてコーディングエラーの検出機能など、単なるイーロン・マスクのブランドを冠した目新しいAIではないことを証明してくれました。
ChatGPTとGrokに関するFAQ|よくある質問
Q:どちらが優れていますか?
A:何を求めているのかによります。
Grokはウィットに富み、フィルタリングがなく、X(旧Twitter)のリアルタイムコンテンツとの連動性が特徴です。ChatGPTはよりプロフェッショナルで、使える機能が豊富です。今回のテストでは、ChatGPTはコーディングや画像生成、リサーチなどの分野でGrokを上回りましたが、要約やリアルタイムプレビューでのエラー処理ではGrokに軍配が上がる結果となりました。
Q:情報はどちらがより正確ですか?
A:ChatGPTです。
特にウェブブラウジングの場合、通常のパターンでは情報ソースの提示によって信頼性が担保されているため、全体的に精度が高い傾向にあります。一方のGrokは、高速で意見が明確ですが、語調や簡潔さを優先して正確性を犠牲にすることがあります。
Q:機能はどちらが優れていますか?
A:ChatGPTです。
カスタムGPTやサードパーティ製プラグイン、ファイル分析のサポートなど、Grok よりも多くの統合機能を提供します。Grokは依然としてチャットベースのインタラクションに重点を置いており、カスタムボットやアプリとの統合は現時点ではサポートしていません。
Q:コーディングにはどちらが適していますか?
A:ChatGPTです。
今回のテストでは、クリーンでエラーのないコードを生成し、分かりやすい説明も加えてくれたため、特に開発初心者や非エンジニアに最適です。Grokはテストでは優れたデバッグ機能を備えていましたが、コードが完全に機能するまでにはいくつかの修正が必要でした。
Q:学習やリサーチにはどちらが適していますか?
A:ChatGPTです。
強力な要約機能や構造化された解説、そしてDeep ResearchによるWebアクセス機能によって、学習や調査の分野では優位に立っています。Grokも学術的なコンテンツを扱うこと自体はできますが、どちらかというとカジュアルなクエリやリアルタイム情報に適しています。
Q:数学や問題解決にはどちらが適していますか?
A:ChatGPTです。
数学の問題を解いたり論理を説明したりする場合には、より正確で信頼性が高いです。特にSTEM系の課題において、段階的な問題を上手に処理してくれます。Grokもサポートしてはいますが、数式や精度が求められるクエリでは、ChatGPTほどの精度は期待できません。
Q:クリエイティブなタスクにはどちらが適していますか?
A:互角です。
Grokはユーモアと個性のある回答が得意です。遊び心のあるコピーや型破りなアイデアを提供してくれるでしょう。ChatGPTはより優れた構成とトーンコントロールを備えているため、洗練された文章やストーリーテリング、プロフェッショナルなコンテンツ作成に最適です。
まとめ:それぞれのAIの得意領域を理解することが大切
本記事では、そんなChatGPTとGrokについて、文章生成やコーディングから、画像解析やデータ分析まで、合わせて10個のテスト項目を用意して徹底比較していきました。
今回は十番勝負という形式上、明確な勝者を決めることにはなりましたが、重要なのは1つのAIを選択することではないということです。
それぞれのAIの得手不得手を理解しながら、適材適所に応じて、自分のタスクに合ったAIツールを利用することが何よりも大切です。今回のテストは、それぞれのAIの得意領域を把握するための手段として、読者の皆さまにとっての一助になれれば幸いです。
今後もITreview では、日々進化を続けるAIの最新情報について、ユーザーの皆様へ真に価値あるコンテンツをお届けしていきます。AIツールの選定にお悩みの方やIT業界の最新トレンドに関心のある方などは、ぜひ他の記事もチェックしてみてください。