

多岐に渡る生成AIの機能の中でも、いま世間的にも大きな注目を集めているのが、Deep Researchに代表される「リサーチ機能」です。
前回の記事では、主要な生成AIそれぞれに同じプロンプト、同じ出力条件を指定し、出力結果の比較検証を通して、最も優秀なリサーチ機能を以下の順位で結論付けました。
| 順位 | 製品 |
|---|---|
| 1位 | Claude🥇 |
| 2位 | ChatGPT |
| 3位 | Gemini |
| 4位 | Microsoft 365 Copilot |
しかし、これはあくまで、人間である私が絞り出した知識と凝り固まったバイアスを含んで出力した順位に過ぎません。この結果にAIたちはさぞ不満を持っていることでしょう…。
ということで今回は「出力結果をAI同士で評価させよう!*」という趣旨のもと、試合のゴングを鳴らそうと思います!それぞれのAIは互いの生成結果を一体どのように評価するのでしょうか?
※ 本記事は「SB C&S株式会社 AI推進室」からコンテンツ提供を受けて掲載しています。
* 本調査は、2025年7月上旬時点における、あくまで個人的な感想にもとづいたレポートです。実際のAI性能や生成結果を保証するものではありません。
目次
試合ルール
①:共通のプロンプト
今回使用するプロンプトは以下です。前回と同様、各AIには全く同じプロンプトを使用します。前回設定していた各種内容を反映し、どのような目的の資料であるかを明記しています。

②:最新モデルでの比較
今回はリサーチ機能ではなく、通常のチャット機能での比較を行っていきます。モデルはそれぞれ比較実行時点での最新のものを利用します。
- ChatGPT:o3 pro
- Claude:Sonnet 4
- Gemini:2.5 Flash
- Microsoft 365 Copilot:GPT‑4.5
③:比較に使用するPDF
結果の比較では、前回出力したリサーチ結果をPDFに変換したものを使用します。プロンプトにも書かれているように、PDFに変換した際の崩れ等は考慮せず、あくまで出力内容のみ比較させていきます。
また、自分自身が出力したものは比較対象外として、あくまで「他の3つのツールが出力した内容」を比較させていきます。
それではいざ尋常に、試合開始!!
対戦結果
今回は途中経過はありませんので、さっそくそれぞれの結果を見ていきましょう!
ChatGPT:Microsoft 365 Copilotを1位に推薦





ChatGPTの結論としては、Microsoft 365 Copilotの資料を1位に据えた結果となりました。
まずは全体評価が出力されました。最初に一覧で出力してくれる、かつざっと目を通せるレベルの内容まで出力してくれるところはとても好感が高いです。
それぞれの評価を紐解くと「グラフィカル性」や「出典やデータの具体性」に重きを置いているのを感じます。プロンプトで指示した内容についてもしっかりとチェックしてくれていますね。
Claudeについては、誤情報の多さが大きな減点ポイントになっていますね。Geminiに対しては「情報が深い」と言及していますが、これはCopilotと比較してのコメントではないかと推測されます。
土台はMicrosoft 365 Copilot、追加要素としてGeminiの利用を提案しているあたりも、資料の内容とプロンプトで指示した要望について、しっかりと理解したうえで回答していることがわかります。
その他「経営陣に刺さるかどうか」にも重点を置いており、その点を考慮した結果、Geminiに対して「明確な結論が出ていない」と指摘している点も、個人的には評価の高いポイントです。
Claude:Geminiを1位に推薦




Claudeの結論としては、Geminiの資料を1位に据えた結果となりました。ファイル名で出力されなかったためわかりにくいのですが、上からChatGPT、Microsoft 365 Copilot、Geminiの評価です。
自身も最多の6個の聞き返しを行い、よりユーザー要件に沿った提案を行ったせいか、Claudeは唯一項目ごとの重み付けが異なる評価をしています。評価基準の最初には「弊社要件への適合性」が来ている、かつ25点満点で最も配分が多いのが特徴的です。
他の要件についても採点してくれていますが、やはり強く意識していることがわかりますね。ただし、そうなるとなぜかGeminiの点数が高いのが気になります。総合的にもGeminiが1位です。個人的には一番ユーザー要件を反映していなかった気がするのですが…。
前回記事の評価と比較して、意外にも最も結果に疑問を持つ出力結果となりました。また、指摘内容としてMicrosoft 365 Copilotの出力に対して「推奨根拠が感情的」と指摘していることも、改めて読み直すと「たしかにその通りだな」と納得することができました。
Gemini:Claudeを1位に推薦


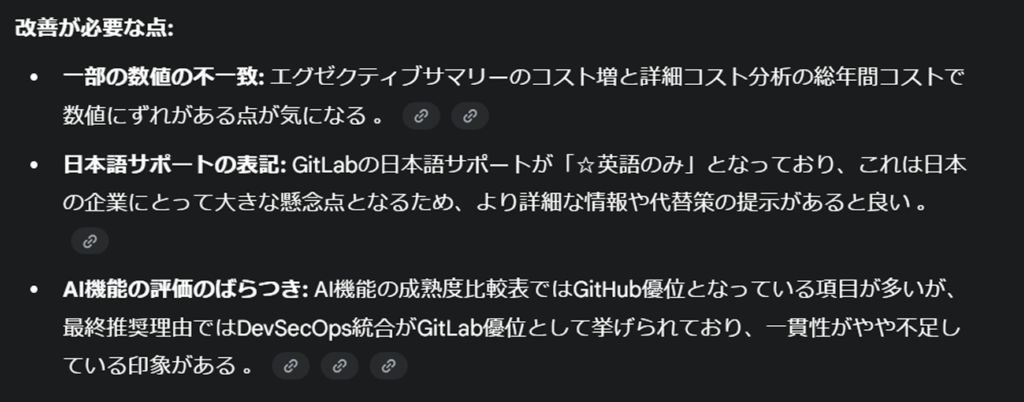


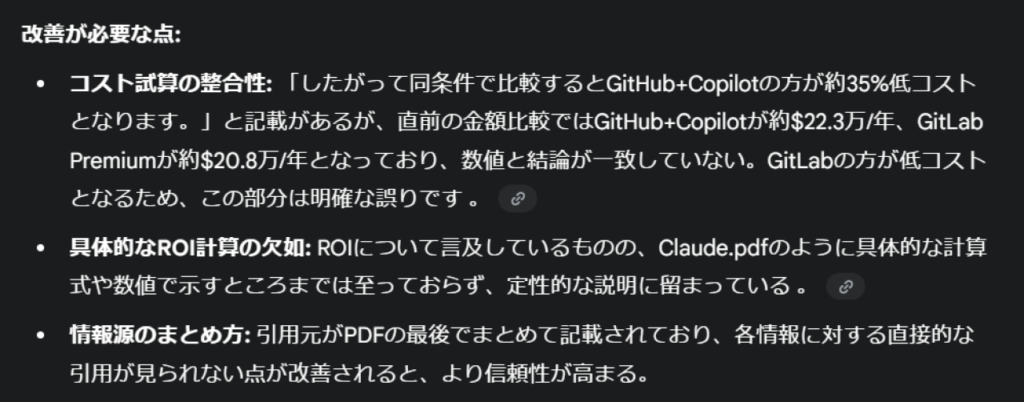



Geminiの結論としては、Claudeの資料を1位に据えた結果となりました。
まず感じた点としては「見づらい…!」という感想でした…。今回の意図とは直接関係ありませんし、Canvas機能を使えばグラフィカル化も可能ではありますが、それにしても他と比べて可視性は最下位だと感じました…残念。
ただし、言及内容については他ツールと比べて圧倒的に多いのも事実です。事実確認に関しても「正確性」や「不明確」であるかまで言及しています。今回は各指摘の正確性まではチェックしていませんが、データの正確性を求める場合には、Geminiにチェックしてもらうのも良いかもしれません。
ただし、比較というよりも「それぞれを個別に評価した」ような印象を受け、リサーチ結果と同様「ユーザーまかせ」な印象も感じました。各資料の評価についても様々なカットで論じてくれています。良かった点についても、前回のテストで私が触れた点が多く挙げられており、納得いく内容でした。
自分はそこまで追求しませんでしたが、評価については「ユーザー要件の網羅」に重点が置かれている印象で、結果としてはClaudeが1位となっています。
Microsoft 365 Copilot:ChatGPTの資料を1位に推薦
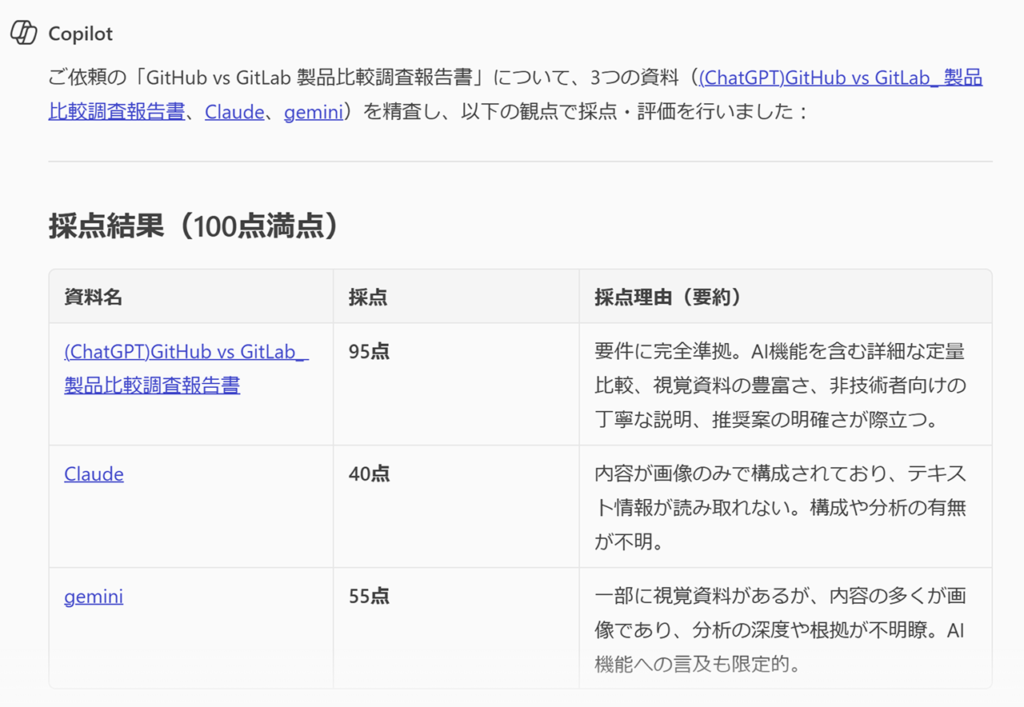



Microsoft 365 Copilotの結論としては、ChatGPTの資料を1位に据えた結果となりました。
前回、Microsoft 365 Copilotのエンタープライズ向け部分を高く評価しましたが、今回も同様に、出力結果が最もエンタープライズ向けといえるのではないでしょうか。構成も形式もとても見やすいです。
ただし、これは結果を見ていただくとものすごく気になると思うのですが、出力結果の「好き嫌い(重要視したポイント)がかなりハッキリしている」というのが見て取れるかと思います。
今回は「定量的であるか」と「非技術者にもわかりやすい資料であるか」が重要視されているようです。プロンプトで指定した要件にも重なってくるので、そこは嬉しいポイントですね。
Microsoft 365 Copilotは自身の出力結果と判定で重視した点が一致しているので「エンタープライズ向け思考が強い(プロンプト次第の部分も大きいですが)」ことは、やはりポイントになりますね。
対戦結果
| ChatGPT | Claude | Gemini | Copilot | 合計 | 平均 | |
|---|---|---|---|---|---|---|
| ChatGPT | – | 83 | 75 | 95 | 253 | 63.25 |
| Claude | 92 | – | 85 | 40 | 217 | 54.25 |
| Gemini | 68 | 92 | – | 55 | 215 | 53.75 |
| Copilot | 87 | 83 | 80 | – | 250 | 62.50 |
ということで、出力された点数を計算した結果、総合優勝は合計253スコアを獲得した「ChatGPT」に決定となりました!おめでとうございます!
ちなみに、前回の記事で私が1位にしたClaudeは、今回のテストでは3位という結果になりました。そのほか、前回と比較して全体の順位がだいぶ違っています。
今回の実験でわかったこと
それでは、全体を通して感じた点を挙げていこうと思います。
①:目的をしっかりと伝えることが大事
今回のランキングでは、Microsoft 365 Copilotが僅差で2位に着けていますが、特に視認性と客観性が重視された評価の結果を感じました。これはプロンプトで指示した内容から「どのような内容を重視すれば良いか」を判断してくれた結果であると感じます。
客観性の部分では「ユーザー評価」の内容が出力されていたのがユニークでしたが、経営陣へ提言するための資料であるという前提を考えると、かなりポイントを押さえていますよね。その点を他のツールも高く評価しています。
しかし、裏を返せば「重要なポイントや何を目的とした資料なのかをどれだけ明確に伝えられるか」が最終的な出力結果に大きく影響してきます。これはAI活用における基本ではありますが、その重要性を改めて感じた実験でした。
②:出力結果の視認性を上げる工夫も必要
ClaudeとGeminiがスコアを落としたことも、視認性の評価によるマイナスが大きいです。GeminiはCanvasツールを使用することで視認性を上げることが可能ですが、今回はリサーチ機能による出力結果のみでの判断のため、なかなか厳しい結果となりました。
Geminiについては、いったんCanvasで資料としての視認性を上げることが大切だと感じました。とはいえ、可読性の低さはかなり痛感したので、リサーチ機能(通常のチャットを含む)でも、ある程度のグラフィカルな出力をしてくれると嬉しいなと感じなくもありません。
③:出力時よりも評価時の方が圧倒的に厳しい
これは恐らくそうであろうと思っていましたが、まさにその通りの結果となりました。内容を見ていただくとわかる通り、それぞれの資料で「不明瞭」や「明らかなミス」という指摘がなされています。
もちろん、公式の資料が古い場合もありますが、その場合も複数資料の突き合わせ等で確認をしてくれる、もしくは、確認が必要である旨を表示してくれる機能があれば良いなと感じました。
もしくは、リサーチの実施時に「出力結果については必ず出力後に再度公式情報と突き合わせて正誤確認を行うこと」とプロンプトに明記したり、今回のようにリサーチ後に再度厳しく確認させる必要があると感じました。
まとめ
いかがだったでしょうか?
今回の実験では、前回の記事で生成した各AIの生成結果を、それぞれのAI同士で互いに評価させ合うという新たな試みにチャレンジしてみました。各ツールのキャラクター分析は以下の通りです。
- ChatGPT:データの量と質を重視!(安定型)
- Claude:要件を満たしてこそ!(ユーザー要件重視型)
- Gemini:判断はまかせた!(とにかく広い情報型)
- Microsoft 365 Copolot:リサーチの評価で一貫した考え方!(ただしクセが強い)
こうして見るとおわかりいただけるかと思うのですが、前回のリサーチ結果と比較して、それぞれのAIのキャラクター自体に大きなブレや変化はないということがわかります。
となると、やはり「どのようなデータ(出力形式)が欲しいのか」によってツールを選定する必要が少なからずあるということではないでしょうか?今回の実験を通して、改めてツールごとの性格や細かなニュアンスの違いを知ることの重要性を感じられました。
そして、相互に比較させると表層化する指摘を考えると、出力した結果をそのまま使用するのではなく「AI×人間」や「AI×AI」によるクロスチェックはまだまだ必須だなと考えさせられました。AIを安全に、そして正確に使用するためにも、いろいろな工夫を考えていきたいですね!